Google Images Scraper
Google Images scraper extracts photos from Google Images search results. No limits for number of images extracted!
No data limits!
You can extract thousands of items at the same price — no caps, no throttling.
Server & local version
Launch our scraper on a remote server or run it locally on your PC — your choice.
Try for free
Test a free demo version before committing to the full solution.
Feature requests friendly!
Need a custom feature? Just let us know and we'll add it.
Advanced anti-blocking
Captcha processing and anti-crawler detection system built in.
Speed
Cutting-edge browser imitation technology for the highest-speed data extraction.
Google Images Scraper Features
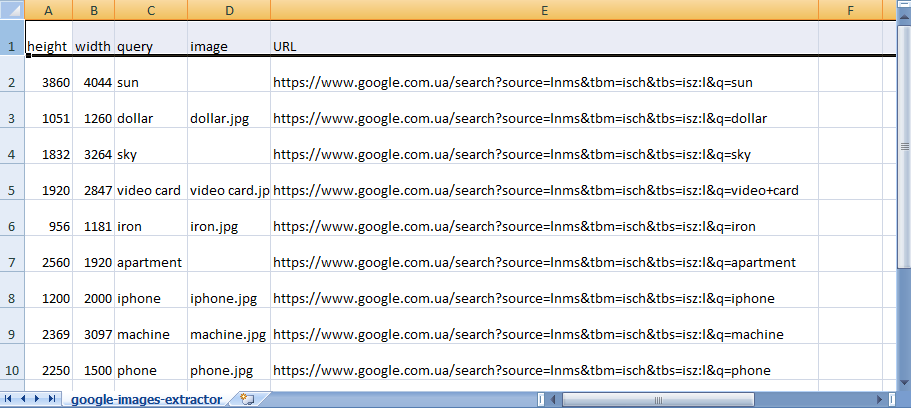
Image URL Extraction
Extract image URLs from Google Images search results, enabling you to download or save desired images quickly and build comprehensive visual content libraries.
Image Details Extraction
Extract additional metadata including image dimensions and the website of origin — valuable information for selecting the most relevant visuals for your needs.
Search Query Input
Input one or multiple search queries to scrape images based on specific keywords, targeting exactly what you need without wasting time on irrelevant results.
Export Possibilities
Export all image data in Excel, CSV, or JSON formats, compiling URLs, dimensions, and source details into a single document ready for analysis.
Frequently Asked Questions
Ready to start scraping?
Book a demo call today and see how our scraper can transform your data collection workflow.