Selector can make XPATH picking process much easier (before inspecting this section please setup XPATH picking settings like this). Usually XPATH picking algorithm is the following:
1. Load page (from where data will be extracted) in Datacol Selector assistant. Datacol loader option should be turned off, because browser mode makes XPATH picking more effective. In current example we want to get post title from page below: "Garmin Edge 500 Cycling GPS (Neutral Color)".
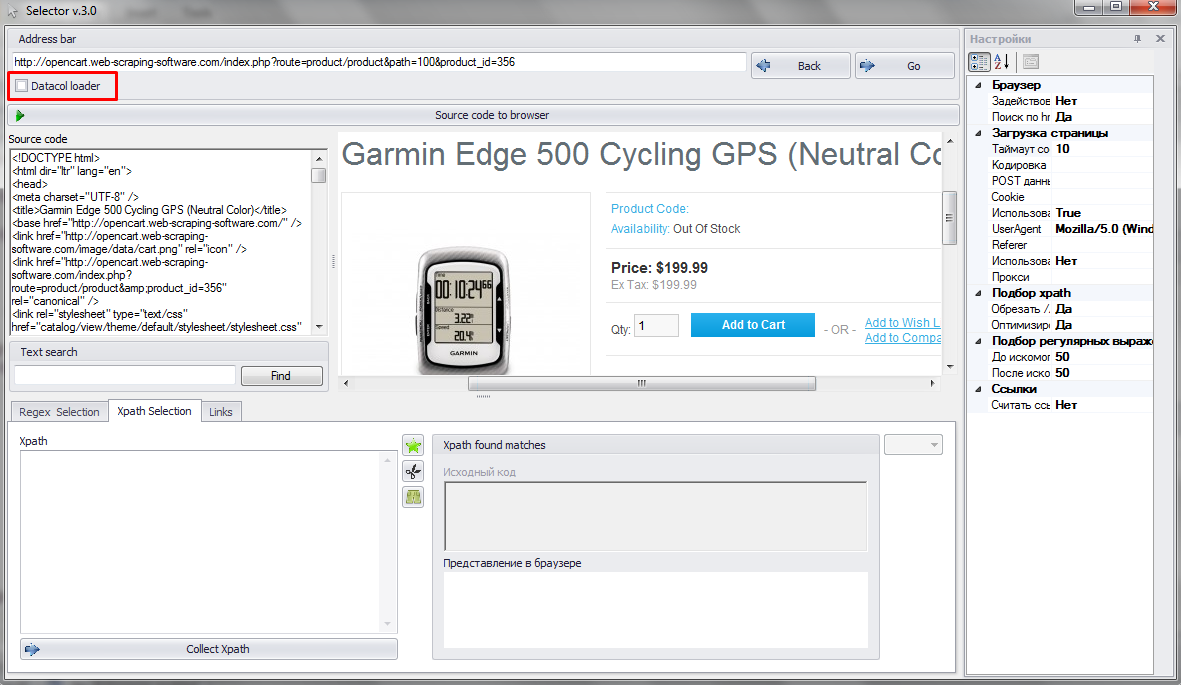
2. Right click on needed block and Selector will automatically generate XPATH to extract this block.
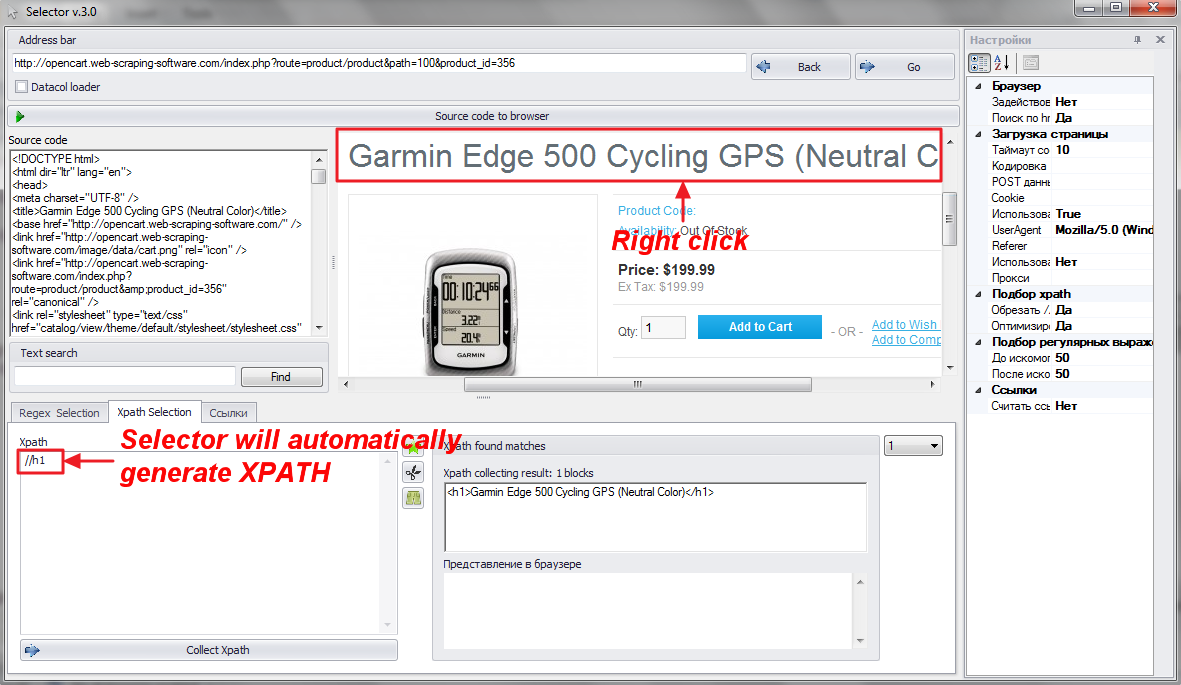
3. Load page with Datacol loader. In this case webpage will be loaded in the same way as Datacol loads it (particularly without Javascript processing). Now we can check if picked XPATH will be also actual here.
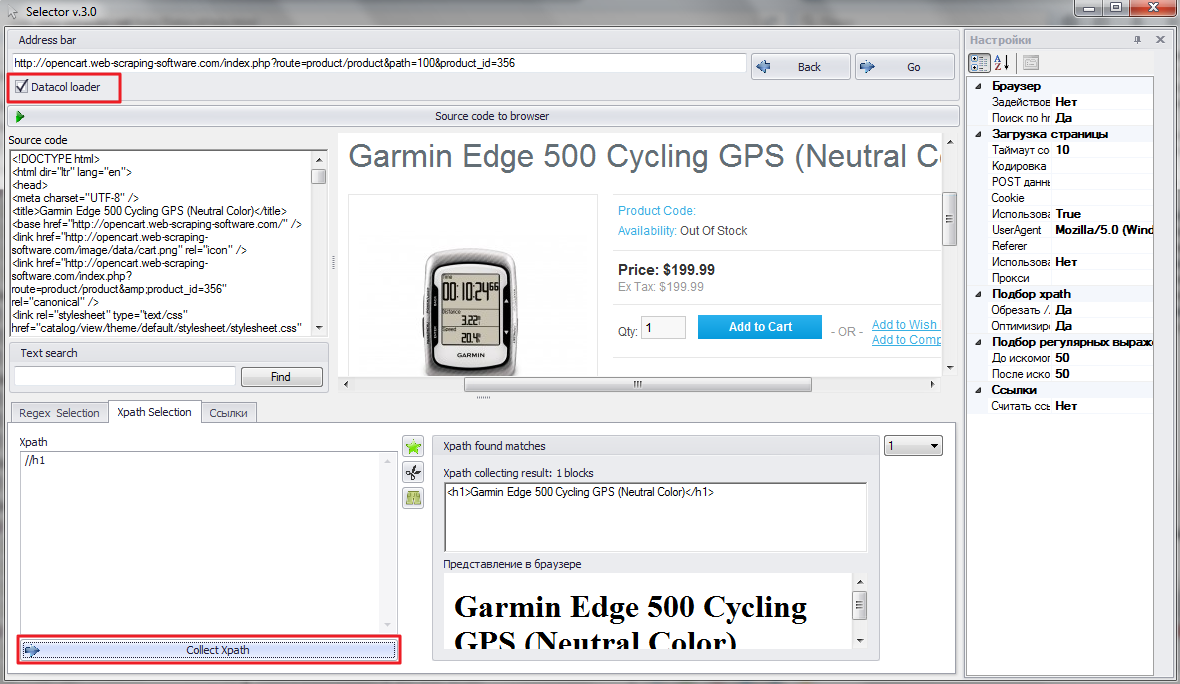
4. If XPATH is still actual (matches are found) you can use XPATH in Datacol.
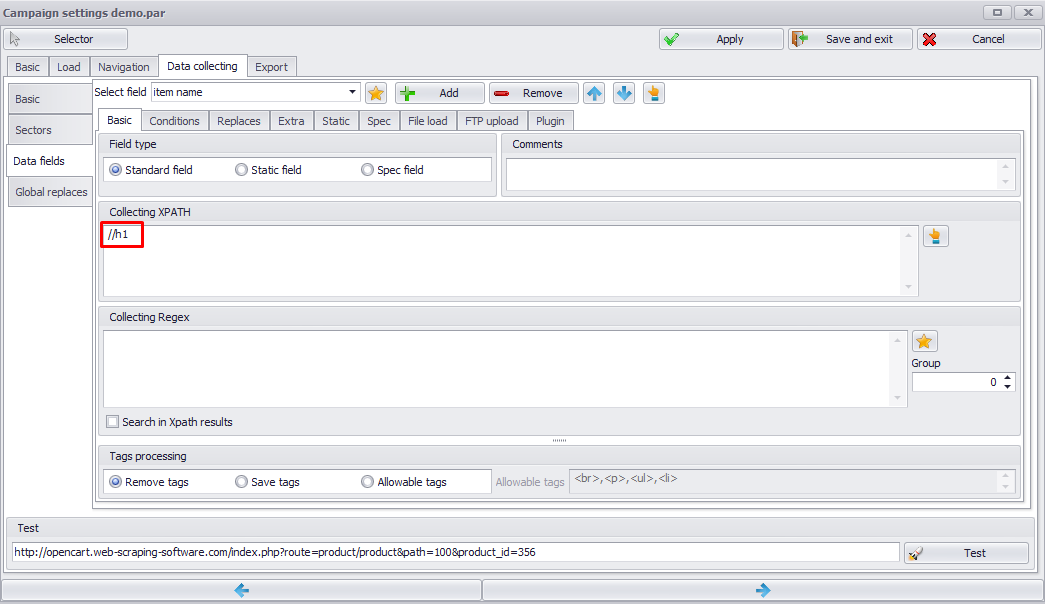
Note, that if XPATH cannot be found (using the above algorithm), just use alternative Regex data extraction mechanism.
Created with the Personal Edition of HelpNDoc: Easily create Help documents